Z przyjemnością informujemy, że Rada Naukowa IPPT PAN nadała mgr. inż. Arturowi Niewiarowskiemu z Politechniki Krakowskiej stopień doktora w dziedzinie nauk inżynieryjno-technicznych, w dyscyplinie informatyka techniczna i telekomunikacja.

Obrona doktoratu w IPPT PAN w dniu 4 grudnia 2024 roku, zdjęcie wraz prof. Januszem Szczepańskim (po lewej stronie)
Tytuł pracy brzmi: „Zastosowanie algorytmu odległości edycyjnej do ilościowej analizy danych tekstowych”. Promotorem jest dr hab. inż. Marek Stanuszek, profesor Politechniki Krakowskiej.
Celem rozprawy doktorskiej było opracowanie i implementacja nowej efektywnej metody pozwalającej na analizę podobieństwa danych tekstowych, niezależnej od systemów leksykalnych większości języków o korzeniach europejskich.
Analiza podobieństwa tekstów stanowi jedno z kluczowych zagadnień w przetwarzaniu języka naturalnego (NLP), znajdując zastosowanie w takich obszarach jak wykrywanie plagiatów, stylometria, tłumaczenia maszynowe, czy analiza semantyczna. Tradycyjne metody porównywania tekstów często opierają się na złożonych procesach leksykalnych, takich jak sprowadzanie słów do ich form podstawowych, czy analiza semantycznych relacji między wyrazami. Podejścia te, choć skuteczne w wielu przypadkach, mogą być ograniczone przez specyfikę danego języka, wymagać dostępu do zaawansowanych technologii lub dużych zbiorów danych, a także wiązać się z wysokimi wymaganiami obliczeniowymi.
Przedstawiona w pracy metoda ma stanowić bazę wyjściową do budowy efektywnych systemów anty-plagiatowych oraz algorytmów stylometrycznych, wykorzystujących pełną moc obliczeniową dzisiejszych komputerów - zarówno domowych jak i przemysłowych (w tym naukowych). Poprzez niezależność leksykalną, należy rozumieć np. brak konieczności implementacji procesów sprowadzania analizowanych wyrazów do ich form podstawowych, jak również wspólnych grup wyrazowych w celu osiągnięcia satysfakcjonującego wyniku analizy. Co istotne, opracowana metoda nie wymaga wykorzystania najnowszych technologii takich jak word2vec czy GloVe, dzięki czemu oferuje bardziej uniwersalne podejście, dostępne także dla użytkowników nieposiadających zaawansowanej infrastruktury obliczeniowej lub dostępu do dużych zbiorów danych uczących. Przekłada się to na uniwersalność mechanizmu względem badanych dokumentów napisanych w danych językach, jak również znacząco przyspiesza jego działanie, ze względu na brak konieczności implementacji wspomnianych procesów. Metoda jest na tyle wydajna, że można ją zainstalować jako oprogramowanie na komputerze o standardowych parametrach obliczeniowych. W ostatnim czasie wiele firm na świecie wprowadziło przepisy zabraniające swoim pracownikom wysyłania dokumentów elektronicznych do chmur obliczeniowych, czyli de facto do firm trzecich, co sprawia, że zamysł tego typu metody powinien dodatkowo zyskać na znaczeniu.
W pracy porównane zostały teksty pod kątem podobieństwa w ramach tych samych języków, jak również teksty napisane w językach pokrewnych, wywodzących się z tych samych grup językowych. Miało to na celu wykazanie skuteczności, w tym przede wszystkim czułości i adaptacyjności mechanizmu do różnych języków. Dane tekstowe poddane analizie pochodziły z różnych źródeł, w tym z popularnych encyklopedii internetowych oraz opracowanych przez tzw. sztuczną inteligencję. Różne wersje językowe tych samych artykułów były efektem tłumaczenia przez translatory języków obcych lub wynikiem opracowania artykułów przez ChatGPT.
W pracy doktorskiej przeprowadzone zostały liczne testy, które dowiodły, że metoda umożliwia precyzyjną identyfikację podobieństw między tekstami, zarówno w ramach tego samego języka, jak i w różnych językach należących do tej samej grupy językowej. Metoda opracowana w ramach pracy jest w stanie również skutecznie identyfikować nadużycia polegające na generowaniu tekstów przez systemy sztucznej inteligencji, takie jak ChatGPT (w różnych jego wersjach). Przeprowadzone testy dowiodły, że analiza zbiorów wypracowań na dany temat umożliwia wykrycie wzorców charakterystycznych dla tekstów generowanych automatycznie, co jest szczególnie istotne w kontekście edukacji i nauki, gdzie oryginalność pracy jest kluczowym kryterium oceny.
 |
 |
 |
|
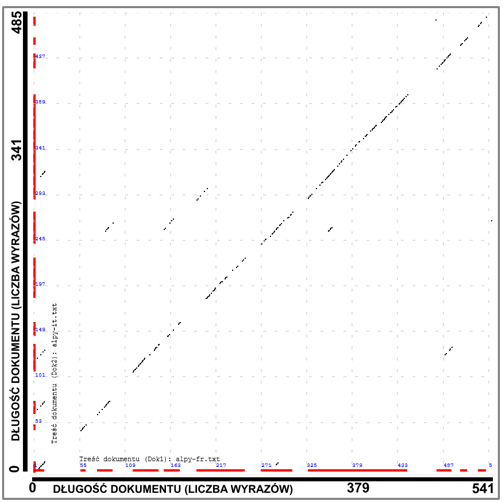
Graficzny wynik podobieństwa tych samych tekstów napisanych w językach: francuskim i włoskim |
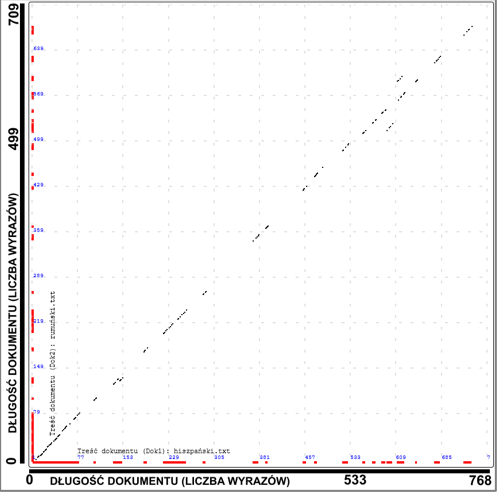
Graficzny wynik podobieństwa tych samych tekstów napisanych w językach: hiszpańskim i rumuńskim |
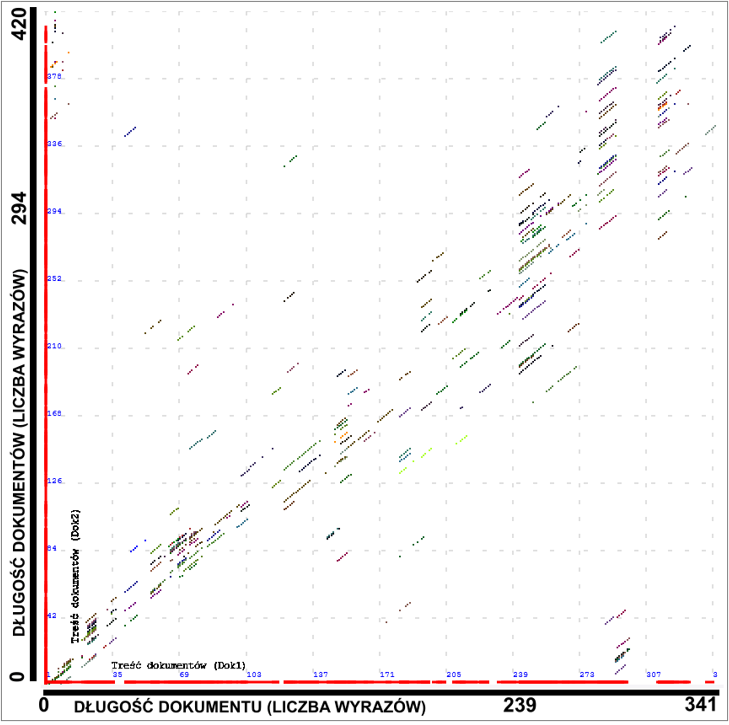
Interpretacja graficzna porównania wypracowania napisanego przez ChatGPT 4o z czterdziestoma tekstami stworzonymi przez ten sam model na ten sam temat |